Last Updated on January 26, 2024 2:34 pm by Laszlo Szabo / NowadAIs | Published on January 26, 2024 by Laszlo Szabo / NowadAIs
Google Lumiere: New Hero on Generative AI Video Models Ground – Key Notes
- Space-Time U-Net Architecture: Unique approach ensuring globally coherent motion in video synthesis.
- Versatility in Applications: Simplifies extension to various content creation tasks and video editing applications.
- Conditional Generation: Supports a wide range of generation tasks, enhancing personalization and context-awareness.
- Robust Training and Evaluation: Trained on a dataset of 30 million videos, ensuring high-quality, diverse content generation.
- Addressing Societal Impacts: Commitment to developing tools for safe and fair use, ensuring ethical implications are considered.
Google Lumiere: Pioneering the New Era of Video Synthesis with AI
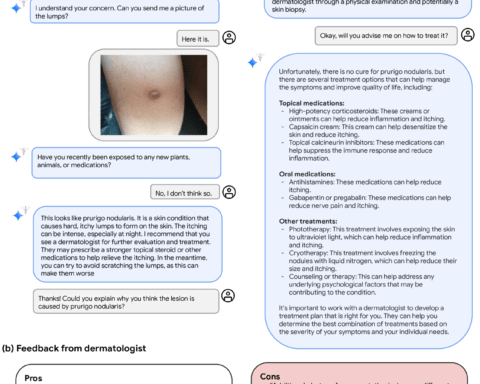
The realm of Artificial Intelligence (AI) has witnessed the introduction of Google Lumiere, a state-of-the-art video model designed to redefine the standards of video synthesis.
By innovatively adopting a Space-Time U-Net architecture, Lumiere addresses the pivotal challenge of portraying realistic, diverse, and coherent motion, which has long been a bottleneck in video synthesis.
A Revolutionary Approach to Video Synthesis
Traditional video models often grapple with maintaining global temporal consistency, primarily because they synthesize videos by creating distant keyframes followed by temporal super-resolution.
Google Lumiere, however, introduces an innovative method that generates the entire temporal duration of a video in one fell swoop, ensuring
“realistic, diverse, and coherent motion”
which has been a significant challenge in video synthesis so far.
The Power of Space-Time U-Net Architecture

At the heart of Google Lumiere is its novel Space-Time U-Net (STUNet) architecture.
This architectural marvel enables both down-sampling and up-sampling in spatial and temporal dimensions. It’s not just about generating longer sequences; it’s about crafting each frame with a higher degree of coherence and fluidity.
As a result, Google Lumiere can generate
“80 frames at 16fps (or 5 seconds, which is longer than the average shot duration in most media”
Leveraging Pre-trained Text-to-Image Diffusion Models
Google Lumiere doesn’t start from scratch.
It smartly builds upon a pre-trained text-to-image diffusion model, learning to generate a full-frame-rate low-resolution video by processing it across multiple space-time scales.
This synergy not only catapults the quality of text-to-video generation but also makes Lumiere adaptable for a wide spectrum of content creation tasks like video inpainting and stylized generation.
Ensuring Temporal Consistency in Video Generation

Temporal consistency is the holy grail in video synthesis, and Google Lumiere achieves it with unparalleled finesse. Other models often falter in generating globally coherent repetitive motion, but Lumiere, with its unique design, ensures high-quality videos with consistent object motion and camera movement throughout the video duration.
MultiDiffusion for Spatial Super-Resolution
Addressing the memory constraints and avoiding temporal boundary artifacts is a tough nut to crack in video synthesis.
Lumiere employs MultiDiffusion along the temporal axis, a technique that ensures smooth transitions between temporal segments of the video, thus maintaining a globally coherent solution over the entire video clip.
This attention to detail in preserving the continuity and coherence of video frames is what sets Google Lumiere apart from the rest.
Conditional Generation Capabilities

Google Lumiere’s architecture allows it to be conditioned on additional input signals like images or masks, enabling a broad spectrum of generation tasks.
This feature is pivotal for tasks that require generating videos starting with a desired first frame or completing masked regions in a video guided by text prompts.
The ability to condition the video generation process on various inputs opens up new horizons for personalized and context-aware video content creation.
Training and Evaluation on Diverse Datasets
Lumiere’s robustness and versatility are further underscored by its training and evaluation on a dataset containing 30 million videos with accompanying text captions.
The model was evaluated using a collection of 113 text prompts describing diverse objects and scenes, showcasing its capability to generate high-quality, diverse content.
This extensive training and evaluation process ensures that Lumiere can handle a wide array of video synthesis tasks, maintaining high standards of quality and relevance to the accompanying text prompts.
Versatility in Downstream Applications
One of the standout features of Lumiere is its versatility and ease of adaptation to a wide range of content creation tasks and video editing applications.
The absence of a temporal super-resolution cascade in Lumiere’s architecture provides an intuitive interface for tasks such as video-to-video editing, style-conditioned generation, and image-to-video inpainting.
These capabilities are particularly beneficial for industries like film, gaming, and AI influence industries – where high-quality video content is paramount.
Competitive Performance and Societal Impact

In terms of performance, Lumiere demonstrates competitive prowess in zero-shot text-to-video generation, achieving notable scores in metrics like Frechet Video Distance (FVD) and Inception Score (IS).
Moreover, it’s imperative to address the societal impacts of such powerful technology.
The creators of Lumiere are conscientious of the potential risks associated with misuse, particularly in creating fake or harmful content like deepfakes. As such, they emphasize the importance of developing tools for detecting biases and ensuring the technology’s safe and fair use.
FAQ Section:
What makes Google Lumiere unique in video synthesis?
Lumiere’s unique Space-Time U-Net architecture ensures the generation of videos with realistic, diverse, and coherent motion, a significant advancement in the field of video synthesis.
How does Lumiere’s architecture benefit video editing and content creation?
Lumiere’s architecture simplifies the extension to various downstream applications, offering an intuitive interface for tasks like video-to-video editing, style-conditioned generation, and image-to-video inpainting.
Can Lumiere be conditioned on additional inputs?
Yes, Lumiere can be conditioned on input signals like images or masks, enabling a broad spectrum of generation tasks and opening new horizons for personalized and context-aware video content creation.
How was Lumiere trained and evaluated?
Lumiere was trained on a dataset containing 30 million videos with text captions and evaluated on a collection of 113 text prompts, demonstrating its capability to generate high-quality, diverse content.
What are the societal implications of Lumiere’s capabilities?
While Lumiere presents significant advancements, its creators emphasize the importance of developing tools for detecting biases and ensuring the technology’s safe and fair use, especially in preventing the creation of fake or harmful content.