Last Updated on April 23, 2024 12:59 pm by Laszlo Szabo / NowadAIs | Published on April 23, 2024 by Laszlo Szabo / NowadAIs
Das Unsichtbare sehen: Adobes VideoGigaGAN KI-Modell bringt verblüffende Details in unscharfe Videos – Wichtige Hinweise
- Adobes VideoGigaGAN AI-Modell verbessert die Auflösung von Videos mit niedriger Auflösung erheblich und gewährleistet feine Details und zeitliche Konsistenz.
- Basiert auf der Technologie von GigaGAN für das Upsampling von Bildern, erweitert auf Videos.
- Verwendet eine asymmetrische U-Net-Architektur mit zusätzlichen zeitlichen Aufmerksamkeitsebenen, um die Konsistenz über mehrere Frames hinweg zu erhalten.
- Überwindet gängige VSR-Probleme wie Flackerartefakte und Aliasing mit fortschrittlichen Modulen wie der flussgesteuerten Ausbreitung.
- Überlegene Leistung bei der Hochskalierung von Videos mit bis zu 8-facher Auflösung unter Beibehaltung komplizierter Details und realistischer Texturen.
Einführung
Video Super-Resolution (VSR) ist seit langem eine anspruchsvolle Aufgabe in den Bereichen Computer Vision und Grafik. Ziel ist es, die Auflösung niedrig aufgelöster Videos zu verbessern, feine Details wiederherzustellen und die zeitliche Konsistenz zwischen den Bildern zu gewährleisten. Während frühere VSR-Ansätze eine beeindruckende zeitliche Konsistenz gezeigt haben, sind sie bei der Erzeugung hochfrequenter Details oft unzureichend, was zu unscharfen Ergebnissen im Vergleich zu ihren Bildgegenstücken führt.
Adobe, ein führender Innovator in diesem Bereich, hat mit VideoGigaGAN ein generatives KI-Modellvorgestellt, das diese grundlegende Herausforderung angeht. Aufbauend auf dem Erfolg des groß angelegten Bild-Upsamplers GigaGAN hebt VideoGigaGAN die Video-Superauflösung auf ein neues Niveau und liefert Videos mit erstaunlichen Details und gleichmäßiger Konsistenz.
Die Herausforderung der Video-Super-Resolution
Die Erzielung zeitlicher Konsistenz und hochfrequenter Details in der Video-Superauflösung stellt eine große Herausforderung dar. Bisherige Ansätze haben sich auf die Aufrechterhaltung der zeitlichen Konsistenz konzentriert, indem sie regressionsbasierte Netzwerke und optische Flussausrichtungstechniken verwendeten. Diese Methoden gewährleisten zwar fließende Übergänge zwischen Frames, beeinträchtigen aber oft die Erzeugung detaillierter Erscheinungen und realistischer Texturen. Diese Einschränkung hat Forscher bei Adobe dazu veranlasst, das Potenzial von Generative Adversarial Networks (GANs) für die Video-Superresolution zu untersuchen.
VideoGigaGAN: Ausweitung des Erfolgs von Bild-Upsampling auf Videos
VideoGigaGAN baut auf der soliden Grundlage von GigaGAN auf, einem groß angelegten GAN-basierten Bild-Upsampler, der von Adobe entwickelt wurde. GigaGAN nutzt Milliarden von Bildern, um die Verteilung von hochauflösenden Inhalten zu modellieren und feinkörnige Details in Upsampling-Bildern zu erzeugen. Durch die Aufblähung von GigaGAN in ein Videomodell und die Integration von zeitlichen Modulen zielt VideoGigaGAN darauf ab, den Erfolg des Bild-Upsamplings auf die anspruchsvolle Aufgabe der Video-Superauflösung auszuweiten und dabei die zeitliche Konsistenz zu wahren.
Überblick über die Methode: Verbesserung von Detail und Konsistenz
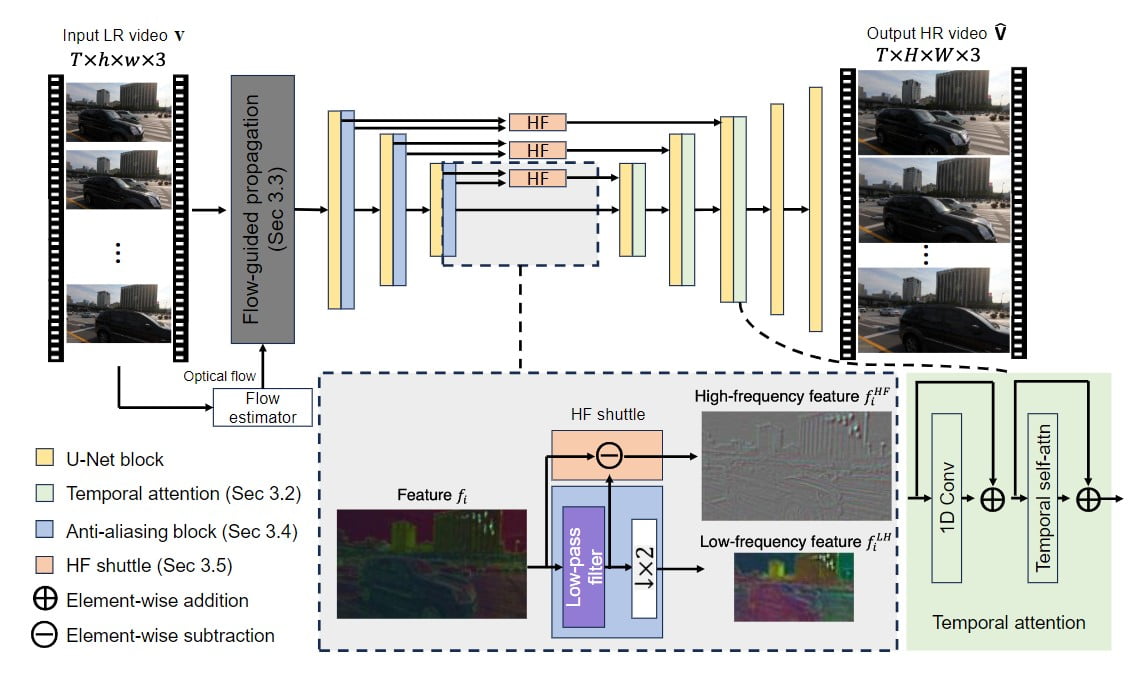
Die Architektur von VideoGigaGAN basiert auf dem asymmetrischen U-Netz, ähnlich wie der GigaGAN-Upsampler für Bilder. Um jedoch zeitliche Konsistenz zu erzwingen, wurden mehrere Schlüsseltechniken eingeführt. Zunächst wird der Bild-Upsampler zu einem Video-Upsampler aufgeblasen, indem zeitliche Aufmerksamkeitsschichten in die Decoderblöcke eingefügt werden. Dadurch wird sichergestellt, dass die erzeugten Frames zeitlich konsistent sind.
Darüber hinaus wird ein flussgesteuertes Ausbreitungsmodul integriert, um die Konsistenz zwischen den Frames durch die Ausrichtung von Merkmalen auf der Grundlage von Flussinformationen zu verbessern. Zur Unterdrückung von Aliasing-Artefakten, die durch Downsampling entstehen, werden Anti-Aliasing-Blöcke in den Encoder integriert. Darüber hinaus werden hochfrequente Merkmale über Skip-Verbindungen direkt zu den Decoderschichten geleitet, um Detailverluste während des Upsampling-Prozesses zu kompensieren.
Ablationsstudie: Überwindung von Flickering-Artefakten und Aliasing
In der Ablationsstudie identifizierten die Forscher von Adobe die starke Halluzinationsfähigkeit des Bildes GigaGAN als Ursache für zeitlich flackernde Artefakte, insbesondere Aliasing, das aus dem niedrig aufgelösten Input resultiert. Um diese Probleme zu lösen, wurden dem Basismodell nach und nach mehrere Komponenten hinzugefügt. Zu diesen Komponenten gehören zeitliche Aufmerksamkeitsebenen, flussgesteuerte Merkmalsausbreitung, Anti-Aliasing-Blöcke und das Hochfrequenz-Shuttle. Durch diese Ergänzungen erreicht VideoGigaGAN ein bemerkenswertes Gleichgewicht zwischen detailreichem Upsampling und zeitlicher Konsistenz, wodurch die bei früheren Ansätzen beobachteten Artefakte und das Flimmern verringert werden.
Vergleich mit State-of-the-Art-Methoden

VideoGigaGAN wurde ausgiebig evaluiert und mit modernsten Video-Super-Resolution-Modellen auf öffentlichen Datensätzen verglichen. Die Ergebnisse zeigen, dass VideoGigaGAN Videos mit wesentlich mehr feinkörnigen Erscheinungsdetails erzeugt, während eine vergleichbare zeitliche Konsistenz beibehalten wird. Durch die Nutzung der Leistungsfähigkeit von GANs und die Einbeziehung innovativer Techniken verschiebt VideoGigaGAN die Grenzen der Video-Superauflösung und bietet ein neues Maß an Realismus und Qualität in hochskalierten Videos.
Upsampling-Ergebnisse: Enthüllung beispielloser Details
Einer der beeindruckendsten Aspekte von VideoGigaGAN ist seine Fähigkeit, Videos um das 8-fache hochzuskalieren und dabei erstaunliche Details zu erhalten. Das Modell zeichnet sich durch die Erzeugung hochfrequenter Details aus, die im niedrig aufgelösten Eingangssignal nicht vorhanden waren, was zu Videos mit einem bemerkenswerten Maß an Realismus und Klarheit führt. Durch den Vergleich der Upsampling-Ergebnisse mit echten Bildern wird deutlich, dass VideoGigaGAN frühere Methoden in Bezug auf Detailerhaltung und Gesamtqualität übertrifft.
Ein Blick in die Zukunft: Umgang mit generischen Videos und kleinen Objekten
Die Fähigkeiten von VideoGigaGAN gehen über spezifische Videokategorien hinaus. Das Modell zeigt eine beeindruckende Leistung bei der Verarbeitung allgemeiner Videos mit unterschiedlichem Inhalt. Allerdings bleiben Herausforderungen bestehen, wenn es um extrem lange Videos und kleine Objekte geht. Zukünftige Forschungen können sich auf die Verbesserung der Schätzung des optischen Flusses und die Bewältigung der Herausforderungen konzentrieren, die mit der Verarbeitung kleiner Details wie Text und Zeichen verbunden sind. Durch die weitere Verfeinerung dieser Aspekte hat VideoGigaGAN das Potenzial, noch größere Möglichkeiten in der Video-Superauflösung zu erschließen.
Schlussfolgerung: Veränderung der Video-Hochskalierung mit VideoGigaGAN
Das KI-Modell VideoGigaGAN von Adobe stellt einen bedeutenden Fortschritt im Bereich der Video-Superauflösung dar. Durch die Nutzung der Leistungsfähigkeit von GANs und die Einbeziehung innovativer Techniken erreicht VideoGigaGAN eine unvergleichliche Detailtreue und Konsistenz bei hochskalierten Videos. Mit seiner Fähigkeit, Videos um das 8-fache hochzuskalieren und dabei feine Details und zeitliche Stabilität beizubehalten, eröffnet VideoGigaGAN neue Möglichkeiten zur Verbesserung von Videoinhalten mit niedriger Auflösung. Da die Nachfrage nach hochqualitativen Videos in verschiedenen Branchen weiter steigt, hat VideoGigaGAN das Potenzial, die Art und Weise, wie wir Videomedien verarbeiten und konsumieren, zu revolutionieren.
Definitionen
- Video-Super-Resolution (VSR): Der Prozess der Konvertierung von Videos mit niedriger Auflösung in eine höhere Auflösung, wobei feine Details wiederhergestellt werden und glatte Übergänge von Bild zu Bild gewährleistet werden.
- GigaGan: Ein leistungsstarkes generatives adversariales Netzwerk, das von Adobe für die Hochskalierung von Bildern entwickelt wurde und für seine Fähigkeit bekannt ist, Bilddetails erheblich zu verbessern.
- VideoGigaGAN: Eine für Videos angepasste Erweiterung von GigaGan, die fortschrittliche KI-Techniken nutzt, um die Auflösung und Qualität von Videos zu verbessern und gleichzeitig die zeitliche Konsistenz zu wahren.
- Zeitliche Konsistenz in Videos: Die Gleichmäßigkeit und Einheitlichkeit von aufeinanderfolgenden Bildern in einem Video, die sicherstellt, dass Verbesserungen den Bewegungsfluss nicht unterbrechen oder störende visuelle Artefakte einführen.
- Asymmetrisches U-Netz: Eine neuronale Netzwerkarchitektur, die für Aufgaben wie die Segmentierung von Bildern verwendet wird und in VideoGigaGAN für die Verarbeitung sowohl der räumlichen als auch der zeitlichen Dimension von Videodaten angepasst wurde.
- Modernste Methoden: Die fortschrittlichsten und effektivsten Techniken, die derzeit in einem bestimmten Bereich verfügbar sind und oft Maßstäbe für Leistung und Effizienz setzen.
Häufig gestellte Fragen
- Was unterscheidet Adobes VideoGigaGAN von anderen Werkzeugen zur Video-Superauflösung? VideoGigaGAN von Adobe verwendet eine einzigartige Kombination aus GAN-Technologie und einer neuartigen U-Net-Architektur, die es ermöglicht, die Videoauflösung zu verbessern und dabei ein hohes Maß an Detailgenauigkeit und zeitlicher Konsistenz zu erhalten, das von früheren Methoden nicht erreicht wurde.
- Kann Adobes VideoGigaGAN Videos mit schnellen Bewegungen oder komplexen Szenen verarbeiten? Ja, VideoGigaGAN wurde entwickelt, um eine Vielzahl von Videoinhalten zu verarbeiten, einschließlich schneller Bewegungen und komplexer Szenen, dank seiner flussgesteuerten Module und zeitlichen Aufmerksamkeitsebenen, die eine reibungslose und detaillierte Ausgabe gewährleisten.
- Was sind die technischen Voraussetzungen, um Adobes VideoGigaGAN AI-Modell effektiv zu nutzen? Die Verwendung des VideoGigaGAN AI-Modells von Adobe erfordert eine robuste Rechenanlage, idealerweise mit Hochleistungs-GPUs wie der NVIDIA RTX-Serie, um die intensive Verarbeitung zu bewältigen, die für die Echtzeit-Videoverbesserung erforderlich ist.
- Wie gewährleistet Adobes VideoGigaGAN den Realismus und die Qualität der hochskalierten Videos? VideoGigaGAN nutzt fortschrittliche KI-Techniken wie generative adversarische Netzwerke, zeitliche Aufmerksamkeit und flussgesteuerte Ausbreitung, um Videos realistisch zu verbessern und sicherzustellen, dass die hochskalierten Videos natürliche Texturen und kohärente Bewegungen beibehalten.
- Welche zukünftigen Verbesserungen können mit Adobes VideoGigaGAN AI-Modell erwartet werden? Zukünftige Versionen von VideoGigaGAN werden sich wahrscheinlich darauf konzentrieren, die Effizienz zu verbessern, den Rechenaufwand zu verringern und die Fähigkeit zu verbessern, noch längere Videos und kleinere Objekte mit größerer Präzision zu verarbeiten.