Octopus V2 der Universität Stanford: On-Device AI schlägt GPT-4 – Wichtige Hinweise
- Octopus V2, entwickelt von der Stanford University, ist ein geräteinternes Sprachmodell, das die Leistung von KI-Agenten bei Softwareaufgaben mit hoher Genauigkeit und geringer Latenz verbessert.
- Es wurde entwickelt, um Datenschutz- und Kostenaspekte zu berücksichtigen, und ist ideal für Edge-Geräte wie Smartphones und VR-Headsets.
- Verwendet einen zweistufigen Prozess für Funktionsaufrufe und erreicht so eine bessere Genauigkeit und Effizienz.
- Verwendet spezielle Token für eine verbesserte Vorhersage von Funktionsnamen und geht das Ungleichgewicht in Datensätzen mit einer gewichteten Cross-Entropie-Verlustfunktion an.
- Trainiert mit dem Gemma-2B-Modell mit den beiden Trainingsmethoden Vollmodell und Lora.
Künstliche Intelligenz auf dem Gerät von der Universität Stanford: Octopus V2
In der sich rasch entwickelnden Landschaft der KI-Agenten und Sprachmodelle sticht Octopus V2 als geräteinternes Sprachmodell für Superagenten hervor. Dieses Modell wurde von einem Team der Stanford University entwickelt und ermöglicht es KI-Agenten, eine Vielzahl von Softwareaufgaben, einschließlich Funktionsaufrufen, mit außergewöhnlicher Genauigkeit und geringer Latenz durchzuführen.
Octopus V2 räumt die Bedenken hinsichtlich des Datenschutzes und der Kosten aus, die mit groß angelegten Cloud-basierten Sprachmodellen verbunden sind, und eignet sich daher für den Einsatz auf Endgeräten wie Smartphones, Autos, VR-Headsets und Personalcomputern.
Der Bedarf an geräteeigenen Sprachmodellen
Sprachmodelle haben den Bereich der künstlichen Intelligenz verändert und ermöglichen die Verarbeitung und das Verständnis natürlicher Sprache. Der Rückgriff auf Cloud-basierte Modelle für Funktionsaufrufe ist jedoch mit Nachteilen verbunden, wie z. B. Bedenken hinsichtlich des Datenschutzes, hohen Kosten für Inferenzen und der Notwendigkeit einer ständigen Wi-Fi-Verbindung. Der Einsatz kleinerer, geräteeigener Modelle kann diese Probleme abmildern, doch stehen sie oft vor Herausforderungen wie langsameren Latenzzeiten und begrenzter Akkulaufzeit. Octopus V2 soll diese Probleme lösen, indem es ein effizientes und genaues geräteinternes Sprachmodell bereitstellt.
Octopus V2: Verbesserte Genauigkeit und Latenzzeit
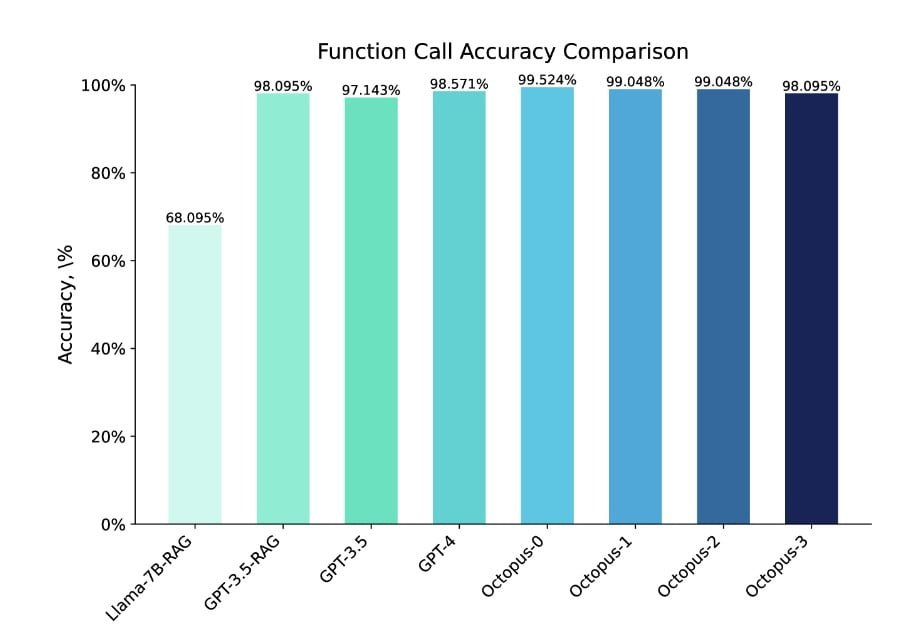
Das Modell Octopus V2 übertrifft die Leistung des GPT-4 sowohl in Bezug auf die Genauigkeit als auch auf die Latenzzeit. Bei 2 Milliarden Parametern reduziert das Octopus-V2-Modell die Kontextlänge um 95 % und ermöglicht so schnellere und effizientere Funktionsaufrufe. Durch die Feinabstimmung des Modells mit funktionalen Token und die Einbeziehung von Funktionsbeschreibungen in den Trainingsdatensatz erreicht das Octopus-V2-Modell eine bessere Leistung beim Funktionsaufruf als andere Modelle. Tatsächlich übertrifft es das Llama-7B-Modell mit einem RAG-basierten Funktionsaufrufmechanismus, indem es die Latenzzeit um das 35-fache erhöht.
Die Methodik: Kausales Sprachmodell als Klassifizierungsmodell
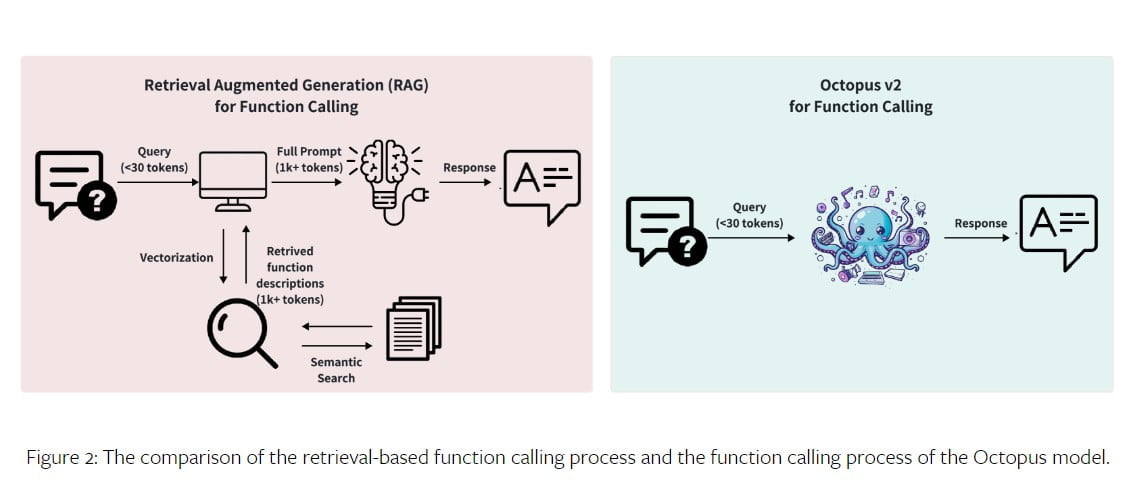
Das Octopus V2-Modell verwendet einen zweistufigen Prozess für den Funktionsaufruf: Funktionsauswahl und Parametergenerierung. In der Phase der Funktionsauswahl verwendet das Modell ein Klassifizierungsmodell, um die geeignete Funktion aus einem Pool von verfügbaren Optionen auszuwählen. Dies kann durch abrufbasierte Dokumentenauswahl oder autoregressive Modelle wie GPT erreicht werden.
In der Phase der Parametergenerierung werden auf der Grundlage der Benutzeranfrage und der Funktionsbeschreibung Parameter für die ausgewählte Funktion erstellt. Das Octopus-V2-Modell kombiniert diese beiden Phasen unter Verwendung einer einheitlichen GPT-Modellstrategie, was zu einer schnelleren Inferenzgeschwindigkeit und einem höheren Systemkomfort führt.
Datensatzsammlung und Modelltraining
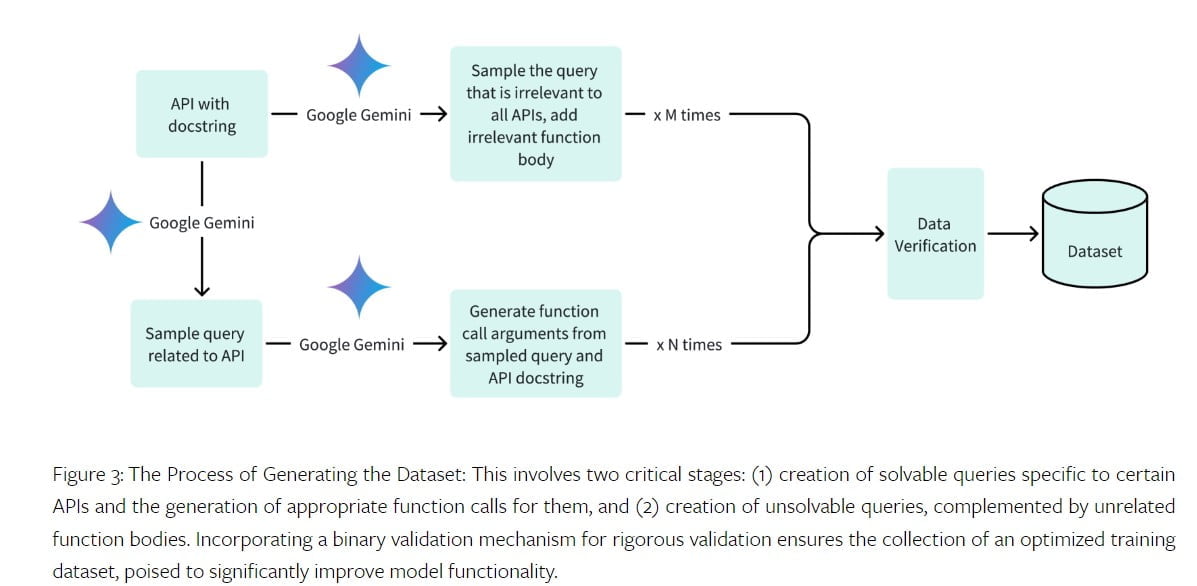
Um das Octopus V2-Modell zu trainieren, ist ein hochwertiger Datensatz erforderlich. Der Datensatz enthält relevante Abfragen, Argumente für Funktionsaufrufe und Funktionsbeschreibungen. Das Team an der Stanford University sammelte Datensätze für verschiedene Domänen, darunter Android-APIs, Fahrzeug-APIs, Yelp-APIs und DoorDash-APIs. Bei der Erstellung des Datensatzes wurden positive Abfragen und Funktionsaufrufargumente für lösbare Abfragen sowie negative Beispiele für unlösbare Abfragen generiert. Der Datensatz wurde mit Hilfe der Google Gemini API überprüft, um Genauigkeit und Vollständigkeit zu gewährleisten.
Das Octopus-V2-Modell wurde mit dem Gemma-2B-Vortrainingsmodell und zwei verschiedenen Trainingsmethoden trainiert: vollständiges Modelltraining und LoRA-Training. Beim Training des vollständigen Modells wurde ein AdamW-Optimierer mit einer Lernrate von 5e-5 und einem Warm-up-Schritt von 10 verwendet. Beim LoRA-Training hingegen wurde ein Rang von 16 verwendet und LoRA auf bestimmte Module des Modells angewendet. Beide Trainingsmethoden erzielten die besten Ergebnisse in Bezug auf Genauigkeit und Latenzzeit.
Darüber hinaus kann die Größe des Trainingsdatensatzes des Octopus V2-Modells angepasst werden, um Kosteneffizienz zu erreichen, ohne die Genauigkeit zu beeinträchtigen. Das Training des Modells mit einem kleineren Datensatz, der zwischen 100 und 1.000 Datenpunkten pro API liegt, liefert immer noch hohe Genauigkeitsraten und macht es für Einzelpersonen zugänglich, die ihre eigenen Octopus-Modelle trainieren möchten.
Benchmarking und Leistungsbewertung
Das Octopus-V2-Modell wurde einem umfassenden Benchmarking und einer Bewertung unterzogen, um seine Effektivität bei der Generierung genauer Funktionsaufrufe zu beurteilen. Die Genauigkeit und die Reaktionszeit des Modells wurden mit führenden Modellen in diesem Bereich, wie GPT-4 und GPT-3.5, verglichen. Das Octopus-V2-Modell übertraf diese Modelle in Bezug auf die Genauigkeit und erreichte im Bewertungsdatensatz eine Genauigkeitsrate von 99,524 %.
Das Modell wies auch eine deutlich geringere Latenzzeit auf, indem es einen Funktionsaufruf innerhalb von 0,38 Sekunden abschloss. Die Leistung des Octopus-V2-Modells wurde in verschiedenen Bereichen bewertet, darunter Android-Funktionsaufrufe, Fahrzeugfunktionsaufrufe, Yelp-APIs und DoorDash-APIs, was seine Vielseitigkeit und Anpassungsfähigkeit unter Beweis stellt.
Feinabstimmung mit speziellen Token
Ein einzigartiger Aspekt des Octopus-V2-Modells ist die Einbindung spezieller Token in den Tokenizer und die Erweiterung des Kopfes des Sprachmodells. Diese speziellen Token stellen Funktionsnamen dar und ermöglichen eine genaue Vorhersage von Funktionsnamen.
Um das Problem des unausgewogenen Datensatzes zu lösen, das durch die Einführung spezieller Token verursacht wird, wird während des Trainings eine gewichtete Kreuzentropie-Verlustfunktion verwendet. Diese gewichtete Verlustfunktion weist den speziellen Token eine höhere Gewichtung zu und verbessert so die Konvergenz und die Gesamtleistung des Modells.
Schlussfolgerung und zukünftige Arbeiten
Das Octopus V2-Modell stellt einen bedeutenden Fortschritt bei geräteinternen Sprachmodellen für Superagenten dar. Durch seine Fähigkeit, genaue Funktionsaufrufe mit reduzierter Latenz durchzuführen, eignet es sich für ein breites Spektrum von Anwendungen, von Smartphones bis hin zu VR-Headsets. Die hohe Genauigkeit und Effizienz des Modells ebnet den Weg für eine verbesserte Leistung von KI-Agenten in realen Szenarien.
In Zukunft kann sich die weitere Forschung und Entwicklung darauf konzentrieren, die Fähigkeiten des Modells zu erweitern, neue Bereiche zu erforschen und seine Leistung für bestimmte Anwendungen zu optimieren.
Definitionen
- Octopus V2: Ein fortschrittliches, von der Stanford University entwickeltes Sprachmodell für Geräte, das die Fähigkeiten von KI-Agenten erheblich verbessern soll, indem es ihnen ermöglicht, Softwareaufgaben mit bisher unerreichter Genauigkeit und Geschwindigkeit auszuführen.
- Stanford-Universität: Eine angesehene Forschungsuniversität, die für ihre bedeutenden Beiträge zu verschiedenen Bereichen bekannt ist, darunter künstliche Intelligenz und Computerwissenschaften.
- On-Device-Sprachmodelle: KI-Modelle, die direkt auf lokalen Geräten wie Smartphones oder Computern arbeiten, ohne dass eine Cloud-Verarbeitung erforderlich ist, wodurch die Privatsphäre betont und die Abhängigkeit von einer ständigen Internetverbindung verringert wird.
- API: Application Programming Interface, eine Reihe von Protokollen und Werkzeugen für die Entwicklung von Software und Anwendungen, die die Kommunikation zwischen verschiedenen Softwarekomponenten ermöglichen.
- Gemma-2B: Ein vortrainiertes Modell, das bei der Entwicklung von Octopus V2 verwendet wurde, um hochwertige Trainingsergebnisse zu erzielen.
- Lora-Ausbildung: Eine Trainingsmethodik, die Low-Rank Adaptation auf spezifische Module eines KI-Modells anwendet, um dessen Leistung zu verbessern, ohne dass ein umfangreiches Neutraining erforderlich ist.
Häufig gestellte Fragen
- Was unterscheidet Octopus V2 von anderen geräteinternen Sprachmodellen?
- Octopus V2 zeichnet sich durch seine Fähigkeit aus, eine breite Palette von Softwareaufgaben mit bemerkenswerter Genauigkeit und reduzierter Latenzzeit auszuführen und gleichzeitig die Datenschutz- und Kostenprobleme von Cloud-basierten Modellen zu lösen.
- Wie verbessert Octopus V2 die Leistung von KI-Agenten in realen Anwendungen?
- Durch die Reduzierung der Kontextlänge um 95 % und die Feinabstimmung mit funktionalen Token ermöglicht Octopus V2 den KI-Agenten eine effizientere Ausführung von Funktionsaufrufen und übertrifft frühere Modelle wie GPT-4 und Llama-7B in Bezug auf Genauigkeit und Latenzzeit.
- Welche Vorteile bietet Octopus V2 für Entwickler und Endbenutzer?
- Für Entwickler bietet Octopus V2 ein leistungsfähiges Tool für die Erstellung reaktionsschneller und leistungsfähiger KI-Anwendungen auf Edge-Geräten. Endnutzer profitieren von schnelleren, präziseren Interaktionen mit KI-Agenten und verbessern so das gesamte Nutzererlebnis.
- Kann Octopus V2 an verschiedene Domänen und Anwendungen angepasst werden?
- Ja, die Vielseitigkeit von Octopus V2 wurde bereits in verschiedenen Bereichen unter Beweis gestellt, darunter Android-APIs, Fahrzeug-APIs und Yelp-APIs, was seine Anpassungsfähigkeit und Effektivität in verschiedenen Umgebungen unter Beweis stellt.
- Welche zukünftigen Entwicklungen können wir vom Octopus-V2-Modell erwarten?
- Die zukünftige Forschung wird sich darauf konzentrieren, die Fähigkeiten von Octopus V2 auf weitere Bereiche auszuweiten, seine Leistung für spezifische Anwendungen zu optimieren und neue Methoden zu erforschen, um seine Genauigkeit und Effizienz weiter zu verbessern.
Last Updated on April 8, 2024 10:44 a.m. by Laszlo Szabo / NowadAIs | Published on April 5, 2024 by Laszlo Szabo / NowadAIs