Octopus V2 de la Universidad de Stanford: La IA en el dispositivo vence al GPT-4 – Notas clave
- Octopus V2, desarrollado por la Universidad de Stanford, es un modelo de lenguaje para dispositivos que mejora el rendimiento de las tareas de software de los agentes de IA con gran precisión y baja latencia.
- Diseñado para abordar los problemas de privacidad y costes, es ideal para dispositivos de vanguardia, como teléfonos inteligentes y auriculares de realidad virtual.
- Utiliza un proceso en dos fases para la llamada a funciones, lo que mejora la precisión y la eficacia.
- Emplea tokens especiales para mejorar la predicción de nombres de funciones y aborda el desequilibrio de los conjuntos de datos con una función de pérdida de entropía cruzada ponderada.
- Se ha entrenado utilizando el modelo Gemma-2B con metodologías de entrenamiento de modelo completo y Lora.
Inteligencia artificial en el dispositivo por la Universidad de Stanford: Octopus V2
En el panorama en rápida evolución de los agentes de IA y los modelos de lenguaje, Octopus V2 destaca como modelo de lenguaje en el dispositivo para superagentes. Desarrollado por un equipo de la Universidad de Stanford, este modelo permite a los agentes de IA realizar una amplia gama de tareas de software, incluida la llamada a funciones, con una precisión excepcional y una latencia reducida.
Octopus V2 resuelve los problemas de privacidad y coste asociados a los modelos lingüísticos a gran escala basados en la nube, por lo que resulta adecuado para su implantación en dispositivos periféricos como teléfonos inteligentes, automóviles, auriculares de realidad virtual y ordenadores personales.
La necesidad de modelos lingüísticos en los dispositivos
Los modelos lingüísticos han cambiado el campo de la IA, permitiendo el procesamiento y la comprensión del lenguaje natural. Sin embargo, depender de modelos basados en la nube para llamar a funciones conlleva inconvenientes como problemas de privacidad, altos costes de inferencia y la necesidad de una conectividad Wi-Fi constante. El despliegue de modelos más pequeños en el dispositivo puede mitigar estos problemas, pero a menudo se enfrentan a retos como una latencia más lenta y una duración limitada de la batería. Octopus V2 pretende superar estas dificultades proporcionando un modelo lingüístico en el dispositivo eficiente y preciso.
Octopus V2: Mejora de la precisión y la latencia
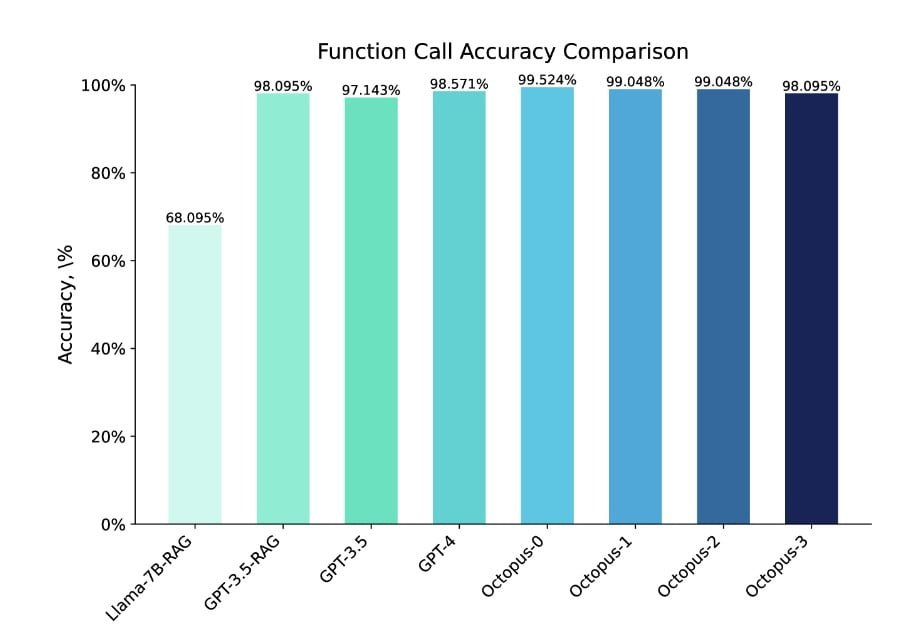
El modelo Octopus V2 supera el rendimiento de GPT-4 tanto en precisión como en latencia. Con 2.000 millones de parámetros, el modelo Octopus V2 reduce la longitud del contexto en un 95%, lo que permite una llamada a funciones más rápida y eficiente. Al ajustar el modelo con tokens funcionales e incorporar descripciones de funciones al conjunto de datos de entrenamiento, el modelo Octopus V2 consigue un mejor rendimiento en la llamada a funciones en comparación con otros modelos. De hecho, supera al modelo Llama-7B con un mecanismo de llamada de funciones basado en RAG al multiplicar por 35 la latencia.
Metodología: Modelo de lenguaje causal como modelo de clasificación
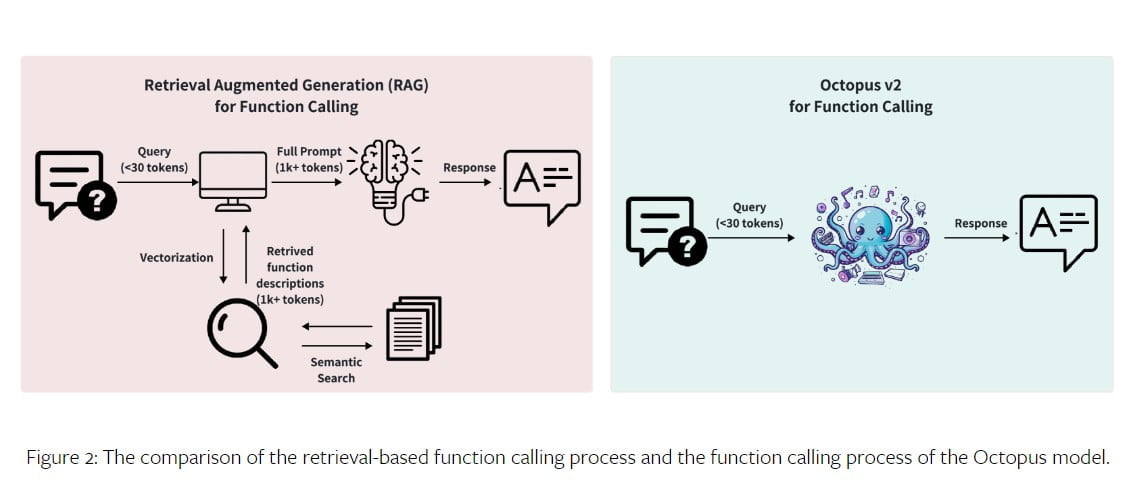
El modelo Octopus V2 utiliza un proceso de dos etapas para la llamada de funciones: selección de funciones y generación de parámetros. En la etapa de selección de funciones, el modelo emplea un modelo de clasificación para seleccionar con precisión la función adecuada de entre un conjunto de opciones disponibles. Esto puede lograrse mediante la selección de documentos basada en la recuperación o modelos autorregresivos como GPT.
La etapa de generación de parámetros consiste en crear parámetros para la función seleccionada a partir de la consulta del usuario y la descripción de la función. El modelo Octopus V2 combina estas dos etapas mediante una estrategia de modelo GPT unificada, lo que se traduce en una mayor velocidad de inferencia y comodidad del sistema.
Recopilación de datos y entrenamiento del modelo
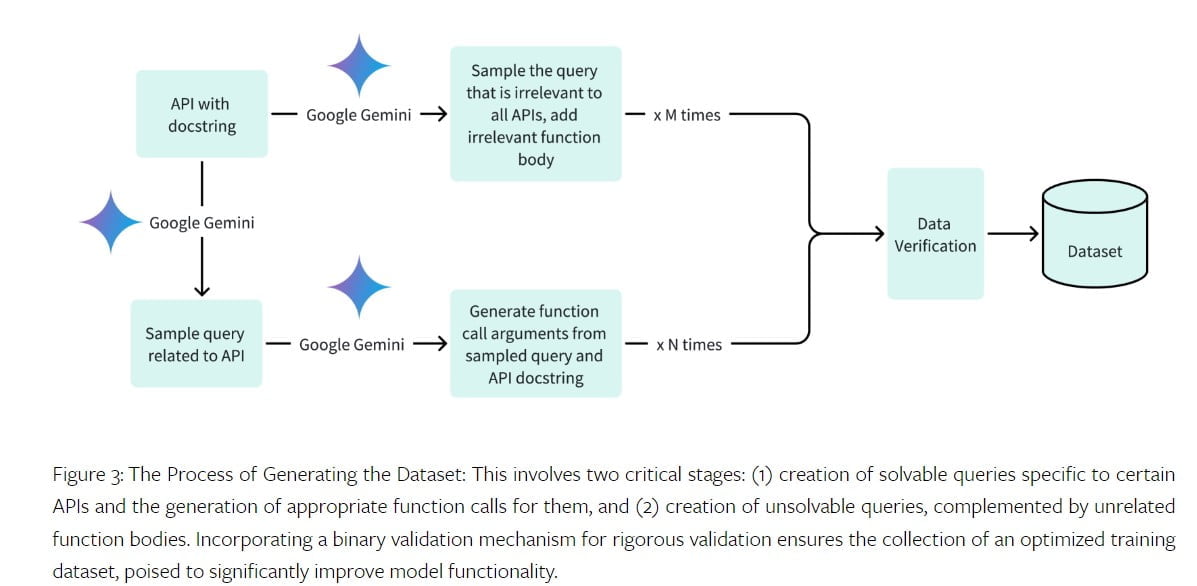
Para entrenar el modelo Octopus V2, es esencial disponer de un conjunto de datos de alta calidad. El conjunto de datos incluye consultas relevantes, argumentos de llamadas a funciones y descripciones de funciones. El equipo de la Universidad de Stanford recopiló conjuntos de datos para diferentes dominios, incluidas las API de Android, las API de vehículos, las API de Yelp y las API de DoorDash. El proceso de generación de conjuntos de datos consistió en generar consultas positivas y argumentos de llamadas a funciones para consultas resolubles, así como muestras negativas para consultas no resolubles. El conjunto de datos se verificó mediante la API Gemini de Google, lo que garantizó su precisión e integridad.
El modelo Octopus V2 se entrenó utilizando el modelo preentrenado Gemma-2B y dos metodologías de entrenamiento diferentes: entrenamiento completo del modelo y entrenamiento LoRA. Para el entrenamiento completo del modelo se utilizó un optimizador AdamW con una tasa de aprendizaje de 5e-5 y un paso de calentamiento de 10. El entrenamiento LoRA, por su parte, utilizó un rango de 16 y aplicó LoRA a módulos específicos del modelo. Ambos métodos de entrenamiento obtuvieron los mejores resultados en términos de precisión y latencia.
Además, el tamaño del conjunto de datos de entrenamiento del modelo Octopus V2 puede ajustarse para lograr una rentabilidad sin comprometer la precisión. Entrenando el modelo con un conjunto de datos más pequeño, de 100 a 1.000 puntos de datos por API, se obtienen altos índices de precisión, lo que lo hace accesible para quienes deseen entrenar sus propios modelos Octopus.
Comparación y evaluación del rendimiento
El modelo Octopus V2 se sometió a una exhaustiva evaluación comparativa para determinar su eficacia a la hora de generar llamadas a funciones precisas. La precisión y el tiempo de respuesta del modelo se compararon con los principales modelos del sector, como GPT-4 y GPT-3.5. El modelo Octopus V2 superó a estos modelos en términos de precisión, alcanzando una tasa de precisión del 99,524% en el conjunto de datos de evaluación.
El modelo también demostró una latencia significativamente reducida, completando una llamada a una función en 0,38 segundos. El rendimiento del modelo Octopus V2 se evaluó en varios dominios, incluidas llamadas a funciones de Android, llamadas a funciones de vehículos, API de Yelp y API de DoorDash, lo que demuestra su versatilidad y adaptabilidad.
Ajuste con tokens especiales
Un aspecto único del modelo Octopus V2 es la incorporación de tokens especiales en el tokenizador y la expansión de la cabeza del modelo lingüístico. Estos tokens especiales representan nombres de funciones y permiten predecirlas con precisión.
Para hacer frente al desequilibrio del conjunto de datos provocado por la introducción de símbolos especiales, durante el entrenamiento se utiliza una función de pérdida de entropía cruzada ponderada. Esta función de pérdida ponderada asigna pesos más altos a los tokens especiales, lo que mejora la convergencia y el rendimiento general del modelo.
Conclusión y trabajos futuros
El modelo Octopus V2 representa un avance significativo en los modelos de lenguaje en dispositivos para superagentes. Su capacidad para realizar llamadas a funciones precisas con una latencia reducida lo hace adecuado para una amplia gama de aplicaciones, desde teléfonos inteligentes a auriculares de realidad virtual. La gran precisión y eficacia del modelo allanan el camino para mejorar el rendimiento de los agentes de IA en escenarios reales.
En el futuro, la investigación y el desarrollo pueden centrarse en ampliar las capacidades del modelo, explorar nuevos dominios y optimizar su rendimiento para aplicaciones específicas.
Definiciones
- Octopus V2: Un modelo avanzado de lenguaje en el dispositivo creado por la Universidad de Stanford, diseñado para mejorar significativamente las capacidades de los agentes de IA permitiéndoles realizar tareas de software con una precisión y velocidad sin precedentes.
- Universidad de Stanford: Una prestigiosa universidad de investigación conocida por sus importantes contribuciones a diversos campos, como la inteligencia artificial y la informática.
- Modelos lingüísticos en dispositivos: Modelos de IA que operan directamente en dispositivos locales, como teléfonos inteligentes u ordenadores, sin necesidad de procesamiento en la nube, haciendo hincapié en la privacidad y reduciendo la dependencia de la conectividad constante a Internet.
- API: Interfaz de programación de aplicaciones, un conjunto de protocolos y herramientas para construir software y aplicaciones, que permite la comunicación entre diferentes componentes de software.
- Gemma-2B: Modelo preentrenado utilizado en el desarrollo de Octopus V2 para lograr resultados de formación de alta calidad.
- Formación Lora: Metodología de entrenamiento que aplica la adaptación de bajo rango a módulos específicos de un modelo de IA para mejorar su rendimiento sin necesidad de un reentrenamiento exhaustivo.
Preguntas más frecuentes
- ¿Qué diferencia a Octopus V2 de otros modelos lingüísticos para dispositivos?
- Octopus V2 destaca por su capacidad para realizar una amplia gama de tareas de software con una precisión notable y una latencia reducida, al tiempo que resuelve los problemas de privacidad y coste de los modelos basados en la nube.
- ¿Cómo mejora Octopus V2 el rendimiento de los agentes de IA en aplicaciones reales?
- Gracias a la reducción de la longitud del contexto en un 95% y al ajuste con tokens funcionales, Octopus V2 permite a los agentes de IA ejecutar llamadas a funciones de forma más eficiente, superando en precisión y latencia a modelos anteriores como GPT-4 y Llama-7B.
- ¿Cuáles son las ventajas de utilizar Octopus V2 para desarrolladores y usuarios finales?
- Para los desarrolladores, Octopus V2 ofrece una potente herramienta para crear aplicaciones de IA capaces y con capacidad de respuesta en dispositivos periféricos. Los usuarios finales se benefician de interacciones más rápidas y precisas con los agentes de IA, lo que mejora la experiencia general del usuario.
- ¿Puede adaptarse Octopus V2 a diversos dominios y aplicaciones?
- Sí, la versatilidad de Octopus V2 se ha demostrado en diferentes dominios, incluidas las API de Android, las API de vehículos y las API de Yelp, lo que demuestra su adaptabilidad y eficacia en diversos entornos.
- ¿Qué desarrollos futuros podemos esperar del modelo Octopus V2?
- La investigación futura se centrará en ampliar las capacidades de Octopus V2 a más dominios, optimizar su rendimiento para aplicaciones específicas y explorar nuevas metodologías para mejorar aún más su precisión y eficacia.
Last Updated on abril 8, 2024 10:48 am by Laszlo Szabo / NowadAIs | Published on abril 5, 2024 by Laszlo Szabo / NowadAIs