

Last Updated on Februar 28, 2024 10:05 am by Laszlo Szabo / NowadAIs | Published on Februar 28, 2024 by Laszlo Szabo / NowadAIs
Einführung von EMO: Emote Portrait Alive – Porträts zu singenden Sensationen mit Alibabas KI – Wichtige Hinweise:
- EMO von Alibaba nutzt ein Audio2Video-Diffusionsmodell für realistische Porträtvideos.
- EMO verbessert die Erstellung von Talking-Head-Videos mit ausdrucksstarker Genauigkeit.
- Es überwindet herkömmliche Grenzen und bietet nuancierte Gesichtsausdrücke anhand von Audiohinweisen.
Lernen Sie EMO von Alibaba kennen: Emote Portrait Alive
In den letzten Jahren hat es im Bereich der Bild- und Videogenerierung erhebliche Fortschritte gegeben.
Eine der jüngsten Entwicklungen in diesem Bereich ist EMO: Emote Portrait Alive, ein vom Institute for Intelligent Computing der Alibaba Group eingeführtes Framework.
EMO nutzt ein Audio2Video-Diffusionsmodell, um ausdrucksstarke Porträtvideos mit bemerkenswertem Realismus und Genauigkeit zu erzeugen.
Durch die Nutzung der Leistungsfähigkeit von Diffusionsmodellen und modernster neuronaler Netzwerkarchitekturen verschiebt EMO die Grenzen dessen, was bei der Erzeugung von Talking-Head-Videos möglich ist.
Der Bedarf an emotionalen Porträtvideos
Die Erstellung von realistischen und ausdrucksstarken Videos mit sprechenden Köpfen ist seit langem eine Herausforderung im Bereich der Computergrafik und der künstlichen Intelligenz.
Herkömmliche Ansätze sind oft nicht in der Lage, das gesamte Spektrum der menschlichen Mimik zu erfassen und natürliche und nuancierte Gesichtsbewegungen zu liefern.
Um diese Grenzen zu überwinden, haben sich die Forscher der Alibaba Group daran gemacht, ein System zu entwickeln, das Audiohinweise präzise in lebensechte Gesichtsausdrücke umsetzen kann.
Das EMO-Framework verstehen
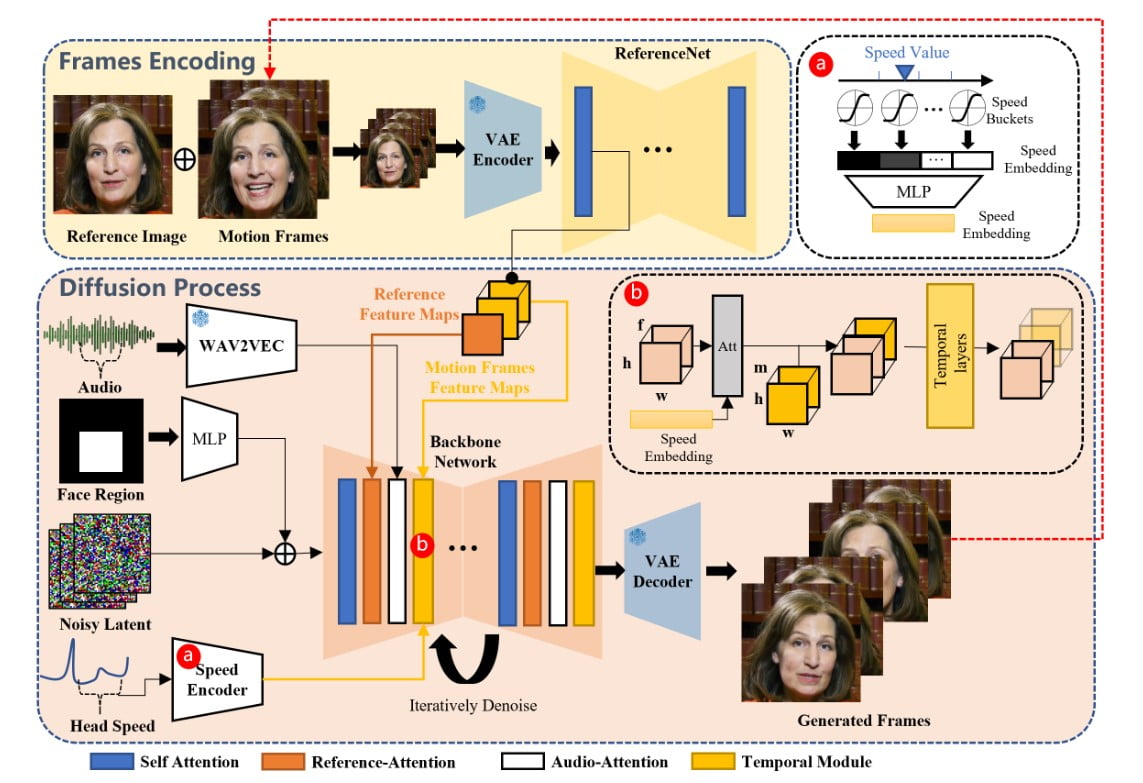
Das EMO-Framework ist ein zweistufiger Prozess, der Audio- und visuelle Informationen kombiniert, um ausdrucksstarke Porträtvideos zu erzeugen.
In der ersten Stufe, der so genannten Frames Encoding, extrahiert ein neuronales Netz namens ReferenceNet Merkmale aus einem einzigen Referenzbild und Bewegungsbildern. Dieser Kodierungsprozess bildet die Grundlage für den anschließenden Diffusionsprozess.
In der Phase des Diffusionsprozesses verwendet EMO einen vortrainierten Audio-Encoder zur Verarbeitung der Audioeinbettung.
Die Maske der Gesichtsregion wird mit Multibildrauschen integriert, das die Erzeugung von Gesichtsbildern bestimmt.
Das Backbone-Netz, das Referenz- und Audio-Attention-Mechanismen umfasst, spielt eine entscheidende Rolle bei der Wahrung der Identität der Figur und der Modulation ihrer Bewegungen.
Zusätzlich werden temporale Module eingesetzt, um die zeitliche Dimension zu manipulieren und die Geschwindigkeit der Bewegung anzupassen.
Durch die Kombination dieser innovativen Techniken ist EMO in der Lage, stimmliche Avatarvideos mit ausdrucksstarker Mimik, verschiedenen Kopfhaltungen und beliebiger Dauer in Abhängigkeit von der Länge des eingegebenen Audios zu erzeugen.
Fortschritte bei der Erzeugung von Gesangsavataren
Mit der Einführung des Konzepts der stimmlichen Avatar-Generierung geht EMO über die traditionellen Talking-Head-Videos hinaus.
Durch die Eingabe eines einzelnen Charakterbildes und eines stimmlichen Audiosignals, wie z. B. Gesang, kann EMO stimmliche Avatarvideos mit ausdrucksstarken Gesichtsausdrücken, verschiedenen Kopfhaltungen und beliebiger Dauer, basierend auf der Länge des eingegebenen Audiosignals, erzeugen.
Singende Avatare
EMO kann singende Avatare erzeugen, die die Gesichtsausdrücke und Kopfbewegungen der Referenzfigur überzeugend nachahmen.
Ob es sich um eine Interpretation von Ed Sheerans “Perfect” oder Dua Lipas “Don’t Start Now” handelt, EMO erweckt die Figur mit bemerkenswerter Genauigkeit und Ausdruckskraft zum Leben.
Die generierten Videos können das Publikum mit ihren lebensechten Darbietungen und der nahtlosen Synchronisation mit dem Audio fesseln.
Mehrsprachige und multikulturelle Ausdrücke
Eine der größten Stärken des EMO-Rahmens ist seine Fähigkeit, Lieder in verschiedenen Sprachen zu unterstützen und unterschiedliche Porträtstile zum Leben zu erwecken.
Mit seiner intuitiven Erkennung von Tonvariationen im Audio kann EMO dynamische und ausdrucksstarke Avatare erzeugen, die die kulturellen Nuancen verschiedener Sprachen widerspiegeln.
Von Mandarin-Covern von David Taos “Melody” bis hin zu japanischen Wiedergaben von “進撃の巨人”-Themensongs ermöglicht EMO den Entwicklern, die Möglichkeiten der mehrsprachigen und multikulturellen Charakterdarstellung zu erkunden.
Schneller Rhythmus und ausdrucksstarke Bewegung
EMO zeichnet sich dadurch aus, dass es die Essenz von schnellen Rhythmen einfängt und ausdrucksstarke Bewegungen liefert, die mit dem Audio synchronisiert sind.
Ob Leonardo DiCaprio zu Eminems “Godzilla” rappt oder KUN KUNs “Rap God”, EMO sorgt dafür, dass selbst die schnellsten Texte mit Präzision und Dynamik wiedergegeben werden.
Diese Fähigkeit eröffnet neue Möglichkeiten für die Erstellung fesselnder Inhalte, wie z. B. Musikvideos oder Performances, die eine komplizierte Synchronisation zwischen Musik und Bildmaterial erfordern.
Mehr als Singen: Sprechen mit verschiedenen Charakteren
EMO ist zwar für seine außergewöhnliche Gesangsavatar-Generierung bekannt, aber es ist nicht nur auf die Verarbeitung von Audio-Inputs durch Gesang beschränkt.
Dieses Framework kann gesprochenes Audio in verschiedenen Sprachen verarbeiten und Porträts aus vergangenen Epochen, Gemälde, 3D-Modelle und KI-generierte Inhalte animieren.
Indem EMO diese Charaktere mit lebensechten Bewegungen und Realismus versieht, erweitert es die Möglichkeiten der Charakterdarstellung in mehrsprachigen und multikulturellen Kontexten.
Gespräche mit ikonischen Figuren
Stellen Sie sich eine Unterhaltung mit Audrey Hepburn, der KI Chloe aus Detroit Become Human oder sogar der rätselhaften Mona Lisa vor – EMO kann diese ikonischen Figuren zum Leben erwecken, indem es ihre Porträts animiert und ihre Lippenbewegungen mit gesprochenem Audio synchronisiert.
Ob es sich um einen Interview-Clip oder einen Shakespeare-Monolog handelt, EMO sorgt dafür, dass die Mimik und die Kopfbewegungen der Figur die Nuancen des Gesprächs genau wiedergeben.
Schauspieler-übergreifende Performances
EMO eröffnet eine völlig neue Dimension der Kreativität, indem es den Porträts von Filmfiguren ermöglicht, Monologe oder Performances in verschiedenen Sprachen und Stilen zu halten.
Von Joaquin Phoenix’ Darstellung des Jokers bis hin zu SongWen Zhangs QiQiang Gao aus “The Knockout” – EMO ermöglicht es Schöpfern, die Möglichkeiten schauspielerübergreifender Performances zu erkunden.
Diese Funktion erweitert die Möglichkeiten der Charakterdarstellung und macht es möglich, Charaktere aus verschiedenen Filmen oder Fernsehsendungen nahtlos in ein einziges Video zu integrieren.
Die Grenzen des Realismus verschieben
Das EMO-Framework verschiebt die Grenzen des Realismus bei der Erstellung von Porträtvideos.
Durch die Umgehung von 3D-Zwischenmodellen oder Gesichtsmerkmalen gewährleistet EMO nahtlose Bildübergänge und eine konsistente Wahrung der Identität im gesamten Video.
Die Integration stabiler Kontrollmechanismen, wie z. B. des Geschwindigkeitsreglers und des Reglers für die Gesichtsregion, erhöht die Stabilität während des Generierungsprozesses. Diese Regler fungieren als subtile Steuersignale, die die Vielfalt und Ausdruckskraft der endgültig generierten Videos nicht beeinträchtigen.
Training und Datensatz
Um das EMO-Modell zu trainieren, wurde ein umfangreicher und vielfältiger Audio-Video-Datensatz erstellt, der aus über 250 Stunden Filmmaterial und mehr als 150 Millionen Bildern besteht.
Dieser umfangreiche Datensatz umfasst ein breites Spektrum an Inhalten, darunter Reden, Film- und Fernsehclips sowie Gesangsauftritte, und deckt mehrere Sprachen wie Chinesisch und Englisch ab.
Die große Vielfalt an Sprech- und Gesangsvideos stellt sicher, dass das Trainingsmaterial ein breites Spektrum menschlicher Ausdrücke und Gesangsstile erfasst und eine solide Grundlage für die Entwicklung von EMO bietet.
Experimentelle Ergebnisse und Benutzerstudie

Um die Leistung von EMO zu bewerten, wurden umfangreiche Experimente und Vergleiche mit dem HDTF-Datensatz durchgeführt.
Die Ergebnisse zeigten, dass EMO die bestehenden State-of-the-Art-Methoden, einschließlich DreamTalk, Wav2Lip und SadTalker, in mehreren Metriken wie FID, SyncNet, F-SIM und FVD übertraf.
Die Nutzerstudie und die qualitativen Auswertungen bestätigten außerdem, dass EMO in der Lage ist, sehr natürliche und ausdrucksstarke Sprech- und Gesangsvideos zu erzeugen und die bisher besten Ergebnisse zu erzielen.
Einschränkungen und zukünftige Entwicklungen
Obwohl EMO erstaunliche Fähigkeiten bei der Erstellung von ausdrucksstarken Porträtvideos demonstriert, gibt es immer noch Einschränkungen, die behoben werden müssen.
Das System ist in hohem Maße von der Qualität der Audioeingabe und des Referenzbildes abhängig, und Verbesserungen bei der audiovisuellen Synchronisation können den Realismus der generierten Videos weiter erhöhen.
Darüber hinaus könnten zukünftige Forschungen die Integration von fortschrittlicheren Emotionserkennungsverfahren untersuchen, um noch nuanciertere Gesichtsausdrücke zu ermöglichen.
Definitionen
- EMO: Emote Portrait Alive: Ein Framework von Alibaba zur Erzeugung ausdrucksstarker Porträtvideos aus Audiodaten, wobei fortschrittliche KI-Techniken für Realismus und Genauigkeit eingesetzt werden.
- Avatar: Eine digitale Darstellung oder Figur, die häufig in virtuellen Umgebungen oder als Online-Nutzeridentität verwendet wird.
- 3D-Modelle: Digitale Darstellungen beliebiger Objekte oder Oberflächen in drei Dimensionen, die in der Computergrafik und Animation verwendet werden.
- HDTF-Datensatz: Ein hochwertiger Datensatz, der in der KI und im maschinellen Lernen verwendet wird, wobei der spezifische Kontext und Inhalt je nach Anwendung variieren kann.
- Alibaba (in Bezug auf KI): Ein führendes globales Unternehmen, das über sein Institute for Intelligent Computing modernste KI-Technologien wie EMO für verschiedene Anwendungen entwickelt.
Häufig gestellte Fragen
- Was ist EMO: Emote Portrait Alive?
EMO ist Alibabas innovatives Framework zur Erstellung von ausdrucksstarken Porträtvideos aus Audio-Inputs unter Verwendung fortschrittlicher KI. - Wie verbessert EMO: Emote Portrait Alive Porträtvideos?
EMO verleiht Porträtvideos mehr Realismus und emotionale Tiefe, indem es Audiohinweise präzise in Gesichtsausdrücke umsetzt. - Kann EMO: Emote Portrait Alive Avatare in mehreren Sprachen erstellen?
Ja, EMO unterstützt mehrsprachige Audioeingaben und ermöglicht so ausdrucksstarke Avatare, die kulturelle Nuancen widerspiegeln. - Welche Arten von Inhalten kann EMO: Emote Portrait Alive animieren?
EMO kann Porträts aus verschiedenen Quellen, darunter historische Figuren, Gemälde und 3D-Modelle, mit lebensechten Bewegungen animieren. - Wodurch unterscheidet sich EMO: Emote Portrait Alive von anderen KI-Technologien?
EMO zeichnet sich durch seine Fähigkeit aus, äußerst ausdrucksstarke und realistische Sprech- und Gesangsvideos zu erzeugen und damit die Grenzen der stimmlichen Avatar-Erzeugung zu überschreiten.








