
Last Updated on February 28, 2024 9:44 am by Laszlo Szabo / NowadAIs | Published on February 28, 2024 by Laszlo Szabo / NowadAIs
Introducing EMO: Emote Portrait Alive – Portraits to Singing Sensations with Alibaba’s AI – Key Notes:
- Alibaba’s EMO utilizes an audio2video diffusion model for realistic portrait videos.
- EMO enhances the generation of talking head videos with expressive accuracy.
- It overcomes traditional limits, offering nuanced facial expressions from audio cues.
Meet Alibaba’s EMO: Emote Portrait Alive
In recent years, the field of image and video generation has witnessed significant advancements.
One of the freshest developments in this domain is EMO: Emote Portrait Alive, a framework introduced by Alibaba Group’s Institute for Intelligent Computing.
EMO utilizes an audio2video diffusion model to generate expressive portrait videos with remarkable realism and accuracy.

By leveraging the power of Diffusion Models and cutting-edge neural network architectures, EMO pushes the boundaries of what is possible in talking head video generation.
The Need for Emotive Portrait Videos
The generation of realistic and expressive talking head videos has long been a challenge in the field of computer graphics and Artificial Intelligence.
Traditional approaches often fall short in capturing the full spectrum of human expressions and fail to deliver natural and nuanced facial movements.
To address these limitations, the researchers at Alibaba Group embarked on a mission to create a framework that could accurately translate audio cues into lifelike facial expressions.
Understanding the EMO Framework
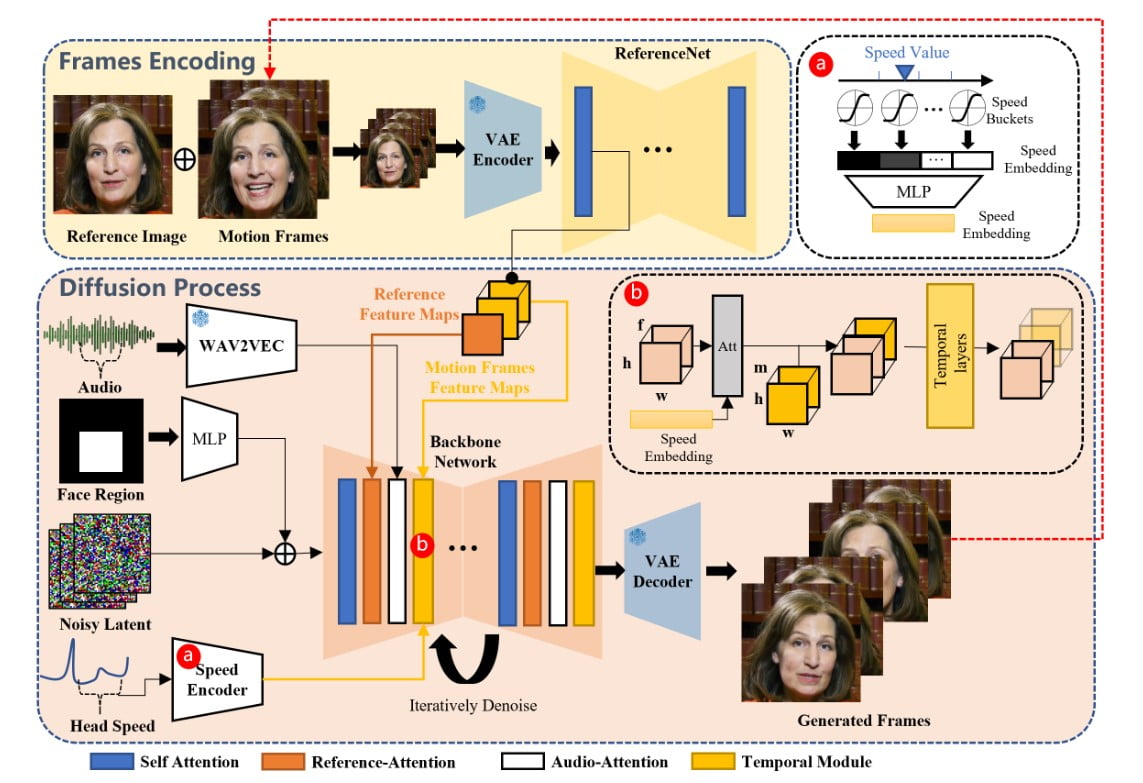
The EMO framework is a two-stage process that combines audio and visual information to generate highly expressive portrait videos.
In the initial stage, called Frames Encoding, a neural network called ReferenceNet extracts features from a single reference image and motion frames. This encoding process lays the foundation for the subsequent diffusion process.
During the Diffusion Process stage, EMO utilizes a pretrained audio encoder to process the audio embedding.
The facial region mask is integrated with multi-frame noise, which governs the generation of facial imagery.
The Backbone Network, incorporating Reference-Attention and Audio-Attention mechanisms, plays a crucial role in preserving the character’s identity and modulating their movements.
Additionally, Temporal Modules are employed to manipulate the temporal dimension and adjust the velocity of motion.
The combination of these innovative techniques enables EMO to generate vocal avatar videos with expressive facial expressions, various head poses, and any duration depending on the length of the input audio.
Advancements in Vocal Avatar Generation
EMO goes beyond traditional talking head videos by introducing the concept of vocal avatar generation.
By inputting a single character image and a vocal audio, such as singing, EMO can generate vocal avatar videos with expressive facial expressions, various head poses, and any duration based on the length of the input audio.
Singing Avatars
EMO can generate singing avatars that convincingly mimic the facial expressions and head movements of the reference character.
Whether it’s a rendition of Ed Sheeran’s “Perfect” or Dua Lipa’s “Don’t Start Now,” EMO brings the character to life with remarkable accuracy and expressiveness.
The generated videos can captivate audiences with their lifelike performances and seamless synchronization with the audio.
Multilingual and Multicultural Expressions
One of the key strengths of the EMO framework is its ability to support songs in various languages and bring diverse portrait styles to life.
With its intuitive recognition of tonal variations in audio, EMO can generate dynamic and expression-rich avatars that reflect the cultural nuances of different languages.
From Mandarin covers of David Tao’s “Melody” to Japanese renditions of “進撃の巨人” theme songs, EMO enables creators to explore the possibilities of multilingual and multicultural character portrayals.
Rapid Rhythm and Expressive Movement
EMO excels at capturing the essence of fast-paced rhythms and delivering expressive movements that are synchronized with the audio.
Whether it’s Leonardo DiCaprio rapping to Eminem’s “Godzilla” or KUN KUN’s rendition of “Rap God,” EMO ensures that even the swiftest lyrics are portrayed with precision and dynamism.
This capability opens up new avenues for creating engaging content, such as music videos or performances that require intricate synchronization between music and visuals.
Beyond Singing: Talking With Different Characters
While EMO is known for its exceptional singing avatar generation, it is not limited to processing audio inputs from singing alone.
This framework can accommodate spoken audio in various languages and animate portraits from bygone eras, paintings, 3D models, and AI-generated content.
By infusing these characters with lifelike motion and realism, EMO expands the possibilities of character portrayal in multilingual and multicultural contexts.
Conversations with Iconic Figures
Imagine having a conversation with Audrey Hepburn, AI Chloe from Detroit Become Human, or even the enigmatic Mona Lisa – EMO can bring these iconic figures to life by animating their portraits and synchronizing their lip movements with spoken audio.
Whether it’s an interview clip or a Shakespearean monologue, EMO ensures that the character’s facial expressions and head movements accurately convey the nuances of the conversation.
Cross-Actor Performances
EMO opens up a whole new realm of creativity by enabling the portraits of movie characters to deliver monologues or performances in different languages and styles.
From Joaquin Phoenix’s rendition of the Joker to SongWen Zhang’s QiQiang Gao from “The Knockout,” EMO allows creators to explore the possibilities of cross-actor performances.
This feature expands the horizons of character portrayal, making it possible to seamlessly integrate characters from different movies or TV shows into a single video.
Pushing the Boundaries of Realism
The EMO framework pushes the boundaries of realism in portrait video generation.
By bypassing the need for intermediate 3D models or facial landmarks, EMO ensures seamless frame transitions and consistent identity preservation throughout the video.
The integration of stable control mechanisms, such as the speed controller and face region controller, enhances stability during the generation process. These controllers act as subtle control signals that do not compromise the diversity and expressiveness of the final generated videos.
Training and Dataset
To train the EMO model, a vast and diverse audio-video dataset was constructed, consisting of over 250 hours of footage and more than 150 million images.
This extensive dataset encompasses a wide range of content, including speeches, film and television clips, singing performances, and covers multiple languages such as Chinese and English.
The rich variety of speaking and singing videos ensures that the training material captures a broad spectrum of human expressions and vocal styles, providing a solid foundation for the development of EMO.
Experimental Results and User Study

Extensive experiments and comparisons were conducted on the HDTF dataset to evaluate the performance of EMO.
The results revealed that EMO outperformed existing state-of-the-art methods, including DreamTalk, Wav2Lip, and SadTalker, across multiple metrics such as FID, SyncNet, F-SIM, and FVD.
The user study and qualitative evaluations further confirmed that EMO is capable of generating highly natural and expressive talking and singing videos, achieving the best results to date.
Limitations and Future Directions
While EMO demonstrates amazing capabilities in generating expressive portrait videos, there are still limitations to be addressed.
The framework relies heavily on the quality of the input audio and reference image, and improvements in audio-visual synchronization can further enhance the realism of the generated videos.
Additionally, future research may explore the integration of more advanced emotion recognition techniques to enable even more nuanced facial expressions.
Definitions
- EMO: Emote Portrait Alive: A framework by Alibaba for generating expressive portrait videos from audio, using advanced AI techniques for realism and accuracy.
- Avatar: A digital representation or character, often used in virtual environments or as online user identities.
- 3D Models: Digital representations of any object or surface in three dimensions, used in computer graphics and animation.
- HDTF Dataset: A high-quality dataset used in AI and machine learning, though the specific context and content may vary by application.
- Alibaba (in AI relation): A leading global company that, through its Institute for Intelligent Computing, develops cutting-edge AI technologies like EMO for various applications.
Frequently Asked Questions
- What is EMO: Emote Portrait Alive?
EMO is Alibaba’s innovative framework for creating expressive portrait videos from audio inputs, using advanced AI. - How does EMO: Emote Portrait Alive enhance portrait videos?
EMO adds realism and emotional depth to portrait videos, accurately translating audio cues into facial expressions. - Can EMO: Emote Portrait Alive create avatars in multiple languages?
Yes, EMO supports multilingual audio inputs, enabling expressive avatars that reflect cultural nuances. - What types of content can EMO: Emote Portrait Alive animate?
EMO can animate portraits from various sources, including historical figures, paintings, and 3D models, with lifelike motion. - What makes EMO: Emote Portrait Alive different from other AI technologies?
EMO stands out for its ability to generate highly expressive and realistic talking and singing videos, pushing the boundaries of vocal avatar generation.








