
Last Updated on febrero 28, 2024 10:24 am by Laszlo Szabo / NowadAIs | Published on febrero 28, 2024 by Laszlo Szabo / NowadAIs
Presentación de EMO: Emote Portrait Alive – Retratos para cantar sensaciones con la IA de Alibaba – Notas clave:
- EMO de Alibaba utiliza un modelo de difusión audio2video para vídeos de retratos realistas.
- EMO mejora la generación de vídeos de cabezas parlantes con precisión expresiva.
- Supera los límites tradicionales, ofreciendo expresiones faciales matizadas a partir de pistas de audio.
Conoce EMO de Alibaba: Emote Portrait Alive
En los últimos años, el campo de la generación de imágenes y vídeos ha experimentado avances significativos.
Uno de los más recientes es EMO: Emote Portrait Alive, un marco presentado por el Instituto de Computación Inteligente del Grupo Alibaba.
EMO utiliza un modelo de difusión de audio y vídeo para generar retratos expresivos con gran realismo y precisión.

Al aprovechar la potencia de los modelos de difusión y las arquitecturas de redes neuronales de vanguardia, EMO amplía los límites de lo posible en la generación de vídeos de cabezas parlantes.
La necesidad de vídeos de retratos emotivos
La generación de vídeos de cabezas parlantes realistas y expresivos ha sido durante mucho tiempo un reto en el campo de los gráficos por ordenador y la Inteligencia Artificial.
Los enfoques tradicionales no suelen captar todo el espectro de expresiones humanas y no consiguen ofrecer movimientos faciales naturales y llenos de matices.
Para hacer frente a estas limitaciones, los investigadores de Alibaba Group se embarcaron en la misión de crear un marco que pudiera traducir con precisión las señales de audio en expresiones faciales realistas.
El marco EMO
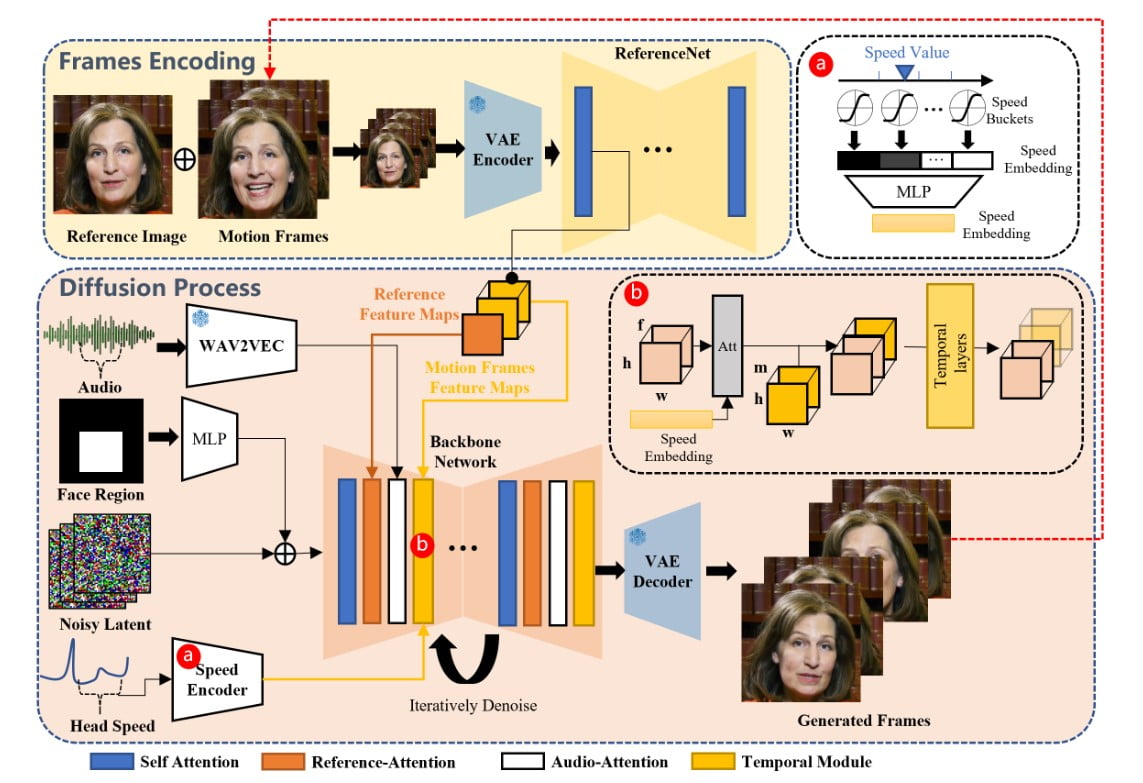
El marco EMO es un proceso de dos etapas que combina información sonora y visual para generar vídeos de retratos muy expresivos.
En la etapa inicial, denominada codificación de fotogramas, una red neuronal llamada ReferenceNet extrae características de una única imagen de referencia y fotogramas de movimiento. Este proceso de codificación sienta las bases para el posterior proceso de difusión.
Durante la etapa del proceso de difusión, EMO utiliza un codificador de audio preentrenado para procesar la incrustación de audio.
La máscara de la región facial se integra con el ruido de varios fotogramas, que rige la generación de imágenes faciales.
La red troncal, que incorpora mecanismos de Reference-Attention y Audio-Attention, desempeña un papel crucial en la preservación de la identidad del personaje y la modulación de sus movimientos.
Además, se emplean Módulos Temporales para manipular la dimensión temporal y ajustar la velocidad de movimiento.
La combinación de estas técnicas innovadoras permite a EMO generar vídeos de avatares vocales con expresiones faciales expresivas, diversas poses de la cabeza y cualquier duración en función de la longitud del audio de entrada.
Avances en la generación de avatares vocales
EMO va más allá de los tradicionales vídeos de cabezas parlantes al introducir el concepto de generación de avatares vocales.
Introduciendo una imagen de un personaje y un audio vocal, como por ejemplo un canto, EMO puede generar vídeos de avatares vocales con expresiones faciales expresivas, diversas posturas de la cabeza y cualquier duración basada en la longitud del audio introducido.
Avatares cantantes
EMO puede generar avatares cantantes que imitan de forma convincente las expresiones faciales y los movimientos de cabeza del personaje de referencia.
Tanto si se trata de una interpretación de “Perfect” de Ed Sheeran como de “Don’t Start Now” de Dua Lipa, EMO da vida al personaje con notable precisión y expresividad.
Los vídeos generados pueden cautivar al público con sus interpretaciones realistas y su perfecta sincronización con el audio.
Expresiones multilingües y multiculturales
Uno de los principales puntos fuertes del marco EMO es su capacidad para admitir canciones en varios idiomas y dar vida a diversos estilos de retrato.
Gracias a su reconocimiento intuitivo de las variaciones tonales del audio, EMO puede generar avatares dinámicos y ricos en expresiones que reflejan los matices culturales de los distintos idiomas.
Desde versiones en mandarín de “Melody”, de David Tao, hasta interpretaciones en japonés de los temas de “進撃の巨人”, EMO permite a los creadores explorar las posibilidades del retrato de personajes multilingües y multiculturales.
Ritmo rápido y movimiento expresivo
EMO destaca por capturar la esencia de los ritmos rápidos y ofrecer movimientos expresivos sincronizados con el audio.
Ya sea Leonardo DiCaprio rapeando “Godzilla” de Eminem o KUN KUN interpretando “Rap God”, EMO garantiza que incluso las letras más rápidas se representen con precisión y dinamismo.
Esta capacidad abre nuevas vías para la creación de contenidos atractivos, como vídeos musicales o actuaciones que requieren una compleja sincronización entre música y efectos visuales.
Más allá del canto: Hablar con distintos personajes
Aunque EMO es conocida por su excepcional generación de avatares cantantes, no se limita a procesar entradas de audio procedentes únicamente del canto.
Este marco puede acomodar audio hablado en varios idiomas y animar retratos de épocas pasadas, pinturas, modelos 3D y contenido generado por IA.
Al infundir movimiento y realismo a estos personajes, EMO amplía las posibilidades de representación de personajes en contextos multilingües y multiculturales.
Conversaciones con personajes icónicos
Imagina tener una conversación con Audrey Hepburn, la IA Chloe de Detroit Become Human o incluso la enigmática Mona Lisa. EMO puede dar vida a estas figuras icónicas animando sus retratos y sincronizando sus movimientos labiales con el audio hablado.
Tanto si se trata de una entrevista como de un monólogo de Shakespeare, EMO garantiza que las expresiones faciales y los movimientos de la cabeza del personaje transmitan con precisión los matices de la conversación.
Actuaciones entre actores
EMO abre todo un nuevo campo de creatividad al permitir que los personajes de una película interpreten monólogos o actuaciones en diferentes idiomas y estilos.
Desde la interpretación del Joker de Joaquin Phoenix a la de QiQiang Gao de SongWen Zhang en “The Knockout”, EMO permite a los creadores explorar las posibilidades de las interpretaciones entre actores.
Esta función amplía los horizontes de la representación de personajes, haciendo posible integrar a la perfección personajes de diferentes películas o programas de televisión en un solo vídeo.
Superar los límites del realismo
El marco EMO amplía los límites del realismo en la generación de retratos en vídeo.
Al prescindir de modelos 3D intermedios o puntos de referencia faciales, EMO garantiza transiciones de fotogramas fluidas y la conservación de una identidad coherente en todo el vídeo.
La integración de mecanismos de control estables, como el controlador de velocidad y el controlador de región facial, mejora la estabilidad durante el proceso de generación. Estos controladores actúan como sutiles señales de control que no comprometen la diversidad y expresividad de los vídeos finales generados.
Entrenamiento y conjunto de datos
Para entrenar el modelo EMO, se construyó un amplio y diverso conjunto de datos de audio y vídeo, compuesto por más de 250 horas de metraje y más de 150 millones de imágenes.
Este extenso conjunto de datos abarca una amplia gama de contenidos, incluidos discursos, clips de cine y televisión, actuaciones de canto, y cubre múltiples idiomas como el chino y el inglés.
La gran variedad de vídeos de discursos y canciones garantiza que el material de entrenamiento capte un amplio espectro de expresiones humanas y estilos vocales, lo que proporciona una base sólida para el desarrollo de EMO.
Resultados experimentales y estudio de usuarios

Se llevaron a cabo amplios experimentos y comparaciones con el conjunto de datos HDTF para evaluar el rendimiento de EMO.
Los resultados revelaron que EMO superaba a los métodos más avanzados, como DreamTalk, Wav2Lip y SadTalker, en varias métricas, como FID, SyncNet, F-SIM y FVD.
El estudio de usuarios y las evaluaciones cualitativas confirmaron además que EMO es capaz de generar vídeos hablados y cantados muy naturales y expresivos, logrando los mejores resultados hasta la fecha.
Limitaciones y perspectivas de futuro
Aunque EMO demuestra unas capacidades asombrosas a la hora de generar vídeos de retratos expresivos, aún quedan limitaciones por abordar.
El marco depende en gran medida de la calidad del audio de entrada y de la imagen de referencia, y las mejoras en la sincronización audiovisual pueden aumentar aún más el realismo de los vídeos generados.
Además, futuras investigaciones podrían explorar la integración de técnicas de reconocimiento de emociones más avanzadas para permitir expresiones faciales aún más matizadas.
Definiciones
- EMO: Emote Portrait Alive: Un marco de Alibaba para generar vídeos de retratos expresivos a partir de audio, utilizando técnicas avanzadas de IA para lograr realismo y precisión.
- Avatar: representación o personaje digital que suele utilizarse en entornos virtuales o como identidad de usuario en línea.
- modelos 3D: Representaciones digitales de cualquier objeto o superficie en tres dimensiones, utilizadas en gráficos por ordenador y animación.
- Conjunto de datos HDTF: Conjunto de datos de alta calidad utilizado en IA y aprendizaje automático, aunque el contexto y el contenido específicos pueden variar según la aplicación.
- Alibaba (en relación con la IA): Empresa líder mundial que, a través de su Instituto de Computación Inteligente, desarrolla tecnologías de IA de vanguardia como EMO para diversas aplicaciones.
Preguntas más frecuentes
- ¿Qué es EMO: Emote Portrait Alive?
EMO es el marco innovador de Alibaba para crear vídeos de retratos expresivos a partir de entradas de audio, utilizando IA avanzada. - ¿Cómo mejora EMO: Emote Portrait Alive los vídeos de retratos?
EMO añade realismo y profundidad emocional a los vídeos de retratos, traduciendo con precisión las señales de audio en expresiones faciales. - ¿Puede EMO: Emote Portrait Alive crear avatares en varios idiomas?
Sí, EMO admite entradas de audio multilingües, lo que permite crear avatares expresivos que reflejan matices culturales. - ¿Qué tipos de contenido puede animar EMO: Emote Portrait Alive?
EMO puede animar retratos de varias fuentes, incluyendo figuras históricas, pinturas y modelos 3D, con movimiento realista. - ¿Qué diferencia a EMO: Emote Portrait Alive de otras tecnologías de IA?
EMO destaca por su capacidad para generar vídeos de voz y canto muy expresivos y realistas, superando los límites de la generación de avatares vocales.







